гҖҗзј–иҖ…жҢүпјҡжҹҗе№ҙжҹҗжңҲжҹҗдёҖеӨ©пјҢ�пјҢпјҢпјҢ�пјҢе®үеҚҡз”өз«һжІ»зҗҶеӯҰйҷўе•ҶеҠЎз»ҹи®ЎдёҺз»ҸжөҺи®ЎйҮҸзі»зі»дё»д»»зҺӢжұүз”ҹж•ҷжҺҲдёҺеҗҢз ҡ们ејҖдјҡпјҢ�пјҢпјҢпјҢ�пјҢиҒҠеҲ°дёӘдәәеҫҒдҝЎй—®йўҳпјҢ�пјҢпјҢпјҢ�пјҢеҗ„дәәжҺҸи„ұжүӢжңәпјҢ�пјҢпјҢпјҢ�пјҢзӣҳй—®жҹҗж”Ҝд»ҳиҪҜ件дёҠиҮӘе·ұзҡ„дҝЎз”ЁеҲҶпјҢ�пјҢпјҢпјҢ�пјҢж•ҲжһңдёҚжҜ”дёҚзҹҘйҒ“пјҢ�пјҢпјҢпјҢ�пјҢзҺӢж•ҷжҺҲзҡ„еҲҶж•°еұ…然жҜ”еҗҢз ҡ们йғҪдҪҺпјҒеҲ«дәәеҸ—еҲәжҝҖдјҡеӨҙжҠўең°пјҢ�пјҢпјҢпјҢ�пјҢж•ҷжҺҲиў«вҖңжғ№жҜӣвҖқжҖҺд№ҲеҠһ�пјҹ�пјҹ�пјҹ�пјҹпјҹеҶҷPaperпјҒдәҺжҳҜе°ұжңүдәҶдёӢйқўиҝҷзҜҮж–Үз« пјҲжң¬ж–Үж‘ҳйҖүиҮӘзҺӢжұүз”ҹж•ҷжҺҲеҫ®дҝЎвҖңзӢ—зҶҠдјҡвҖқпјүгҖ‘
жҲ‘дёӘдәәд»ҘдёәвҖңиҠқйә»дҝЎз”ЁеҲҶвҖқжҳҜдә’иҒ”зҪ‘еҫҒдҝЎиҝҷдёӘиЎҢдёҡйҮҢпјҢ�пјҢпјҢпјҢ�пјҢеҸҜеңҲеҸҜзӮ№еҒҡеҫ—еҫҲдёҚй”ҷзҡ„дёҖдёӘдә§е“Ғ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдҪҶе°ұеғҸдёҖдёӘйҖҡдҝ—дәәдёҖж ·пјҢ�пјҢпјҢпјҢ�пјҢеҶҚдјҳејӮзҡ„дёӘдҪ“пјҢ�пјҢпјҢпјҢ�пјҢйғҪдјҡжңүз”ҹй•ҝзҡ„з–‘еҝғдёҺжҮҠжҒјпјҢ�пјҢпјҢпјҢ�пјҢе°Өе…¶жҳҜеҪ“д»–й•ҝеҫ—еҝ«зҡ„ж—¶й—ҙ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮвҖңиҠқйә»дҝЎз”ЁеҲҶвҖқжүҖдҪ“зҺ°еҮәжқҘзҡ„й—®йўҳпјҢ�пјҢпјҢпјҢ�пјҢжҳҜдә’иҒ”зҪ‘еҫҒдҝЎж•ҙдёӘиЎҢдёҡжҷ®йҒҚдҝқеӯҳпјҢ�пјҢпјҢпјҢ�пјҢиҖҢиў«еҝҪи§Ҷзҡ„дёҖдёӘжҷ®йҒҚй—®йўҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйӮЈе°ұжҳҜзјәд№ҸеҜ№еҫҒдҝЎиҜҜе·®пјҲCredit Scoring Errorпјүзҡ„ж·ұеҲ»зҶҹжӮү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйҖ жҲҗзҡ„ж•Ҳжһңе°ұжҳҜпјҡеҫҒдҝЎжіӣж»Ҙ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдёҚеҲҶе·Ҙе…·пјҢ�пјҢпјҢпјҢ�пјҢдёҚеҲҶеңәжҷҜпјҢ�пјҢпјҢпјҢ�пјҢд»»дҪ•дёҖдёӘжңәжһ„пјҢ�пјҢпјҢпјҢ�пјҢйғҪж•ўеңЁеӨ§ж•°жҚ®зҡ„е№ҢеӯҗдёӢпјҢ�пјҢпјҢпјҢ�пјҢз»ҷдәәжү“еҲҶ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйӮЈд№ҲпјҢ�пјҢпјҢпјҢ�пјҢд»Җд№ҲжҳҜеҫҒдҝЎиҜҜе·®�пјҹ�пјҹ�пјҹ�пјҹпјҹжҲ‘дёҚзҹҘйҒ“иҝҷдёӘеҗҚиҜҚеңЁе·ІеҫҖзҡ„ж–ҮзҢ®дёӯжҳҜеҗҰдҝқеӯҳиҝҮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиӢҘжҳҜжІЎжңүпјҢ�пјҢпјҢпјҢ�пјҢиҜ·еҺҹи°…зҺӢе…Ҳз”ҹиҮӘе·ұзһҺзј–дәҶиҝҷдёӘиҜҚ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдё»иҰҒжғіиҜҙжҳҺдёӢйқўиҝҷд№ҲдёҖдёӘеҺҹзҗҶ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҒҮи®ҫдёҖдёӘдәәзҡ„зңҹе®һдҝЎз”Ёжғ…еҪўжҳҜZпјҢ�пјҢпјҢпјҢ�пјҢиҝҷжҳҜдёҖдёӘд»»дҪ•дәәйғҪзңӢдёҚи§Ғзҡ„жңҖзңҹе®һдҝЎз”Ёжғ…еҪў�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиӢҘжҳҜжҲ‘们зҹҘйҒ“дәҶZпјҢ�пјҢпјҢпјҢ�пјҢеӨ©дёӢдёҠе°ұдёҚеҶҚжңүвҖңеҫҒдҝЎвҖқиҝҷдёӘй—®йўҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢдҝЎз”ЁиҜ„дј°жңәжһ„пјҲдҫӢеҰӮпјҡиҠқйә»пјүзңӢеҲ°дәҶдёҖзі»еҲ—зҡ„пјҢ�пјҢпјҢпјҢ�пјҢеҸҜиғҪеҗҢZзӣёе…ізҡ„жҢҮж ҮпјҲдҫӢеҰӮпјҡж¶ҲиҖ—д№ жғҜгҖҒ收е…ҘзҠ¶жҖҒгҖҒж•ҷиӮІж°ҙдёҖеҫӢпјү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҲ‘们жҠҠиҝҷжүҖжңүзҡ„зӣёе…іжҖ§жҢҮж Үз”ЁдёҖдёӘеҗ‘йҮҸXдҪ“зҺ°�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷйҮҢпјҢ�пјҢпјҢпјҢ�пјҢдҫқиө–дәҺXдёӯ收зҪ—дәҶеҮ еӨҡеҸҜи§Ғзҡ„жҢҮж ҮпјҢ�пјҢпјҢпјҢ�пјҢе®ғзҡ„з»ҙеәҰжңүеҸҜиғҪеҫҲй«ҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйӮЈд№ҲпјҢ�пјҢпјҢпјҢ�пјҢеҫҒдҝЎзҡ„з„ҰзӮ№й—®йўҳе°ұжҳҜпјҡиҰҒйҖҡиҝҮзңӢеҫ—и§Ғзҡ„XпјҢ�пјҢпјҢпјҢ�пјҢжҺЁжөӢзңӢдёҚи§Ғзҡ„Z�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ
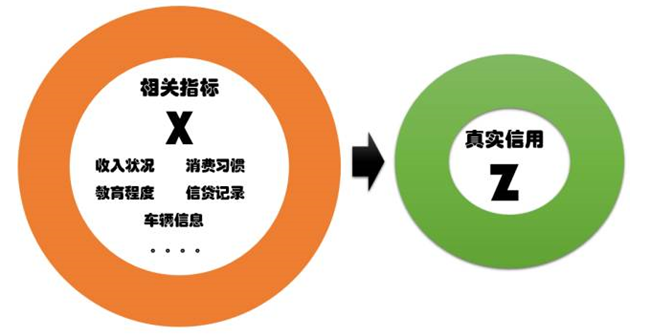
еҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢз»ҷе®ҡXпјҢ�пјҢпјҢпјҢ�пјҢе°ұиғҪеҮҶзЎ®ең°зҹҘйҒ“ZдәҶеҗ—�пјҹ�пјҹ�пјҹ�пјҹпјҹиҷҪ然дёҚеҸҜиғҪ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҲ‘иҮӘе·ұйғҪиҜҙдёҚжё…жҷ°жҲ‘зҡ„ZжҳҜеҮ еӨҡпјҢ�пјҢпјҢпјҢ�пјҢдҪ жҖҺд№ҲзҹҘйҒ“�пјҹ�пјҹ�пјҹ�пјҹпјҹжҲ‘еҖҹдәҶйҡ”йӮ»иҖҒзҺӢ100е…ғпјҢ�пјҢпјҢпјҢ�пјҢиҝҳ�пјҹ�пјҹ�пјҹ�пјҹпјҹз…§ж—§дёҚиҝҳ�пјҹ�пјҹ�пјҹ�пјҹпјҹеҸҜиғҪжҮ’еҫ—иҝҳпјҢ�пјҢпјҢпјҢ�пјҢжҲ‘дҝ©иҖҒзҶҹдәҶпјҢ�пјҢпјҢпјҢ�пјҢиҝҷзӮ№й’ұиҝҳиҰҒиҝҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҲ‘иҰҒжҳҜеҖҹдәҶ100дёҮе‘ў�пјҹ�пјҹ�пјҹ�пјҹпјҹжҲ‘иҰҒжҳҜеҖҹдәҶ100дәҝе‘ў�пјҹ�пјҹ�пјҹ�пјҹпјҹиҝҷиҜҙжҳҺд»Җд№Ҳ�пјҹ�пјҹ�пјҹ�пјҹпјҹиҝҷиҜҙжҳҺз»ҹдёҖдёӘдәәзҡ„ZпјҢ�пјҢпјҢпјҢ�пјҢеҸҜиғҪдјҡйҡҸзқҖеңәжҷҜзҡ„е·®еҲ«иҖҢе·®еҲ«�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷеҸҲиҜҙжҳҺд»Җд№Ҳ�пјҹ�пјҹ�пјҹ�пјҹпјҹиҝҷиҜҙжҳҺзәө然иҮӘе·ұйғҪиҜҙдёҚжё…жҷ°иҮӘе·ұзҡ„ZжҳҜеҮ еӨҡпјҢ�пјҢпјҢпјҢ�пјҢжӣҙеҶөдё”дёҖдёӘеҫҒдҝЎжңәжһ„�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢеҫҒдҝЎжңәжһ„дјҡйҖҡиҝҮXпјҢ�пјҢпјҢпјҢ�пјҢд»ҘеҸҠеӨ§е®—з”ЁжҲ·зңҹе®һзҡ„дҝЎз”ЁиЎҢдёәпјҢ�пјҢпјҢпјҢ�пјҢеӯҰд№ еҮәдёҖдёӘжЁЎеӯҗжқҘ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ然еҗҺпјҢ�пјҢпјҢпјҢ�пјҢйҖҡиҝҮиҝҷдёӘжЁЎеӯҗеҺ»жҺЁжөӢзңҹе®һзҡ„дҝЎз”ЁZ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮж•°еӯҰдёҠжҠҠиҝҷдёӘжҺЁжөӢи®°дҪңпјҡZ*=f(X)�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжІЎй”ҷпјҢ�пјҢпјҢпјҢ�пјҢZ*е°ұжҳҜи°ҒдәәеҫҒдҝЎеҫ—еҲҶпјҲдҫӢеҰӮпјҡиҠқйә»дҝЎз”ЁеҲҶпјүпјҢ�пјҢпјҢпјҢ�пјҢе®ғе°ұжҳҜXзҡ„дёҖдёӘеҮҪж•°�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮз”Ёз»ҹи®ЎеӯҰзҡ„иҜӯиЁҖи®ІпјҢ�пјҢпјҢпјҢ�пјҢZ*жҳҜеҜ№зңҹе®һдҝЎз”ЁZзҡ„дёҖдёӘйў„и®ЎйҮҸпјҲEstimateпјү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ既然Z*жҳҜдёҖдёӘйў„и®ЎйҮҸпјҢ�пјҢпјҢпјҢ�пјҢйӮЈд№Ҳд»–е°ұдёҚдјҡ100%еҮҶзЎ®�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮд»–еҗҢзңҹе®һзҡ„дҝЎз”ЁZд№Ӣй—ҙпјҢ�пјҢпјҢпјҢ�пјҢдјҡжңүдёҖдёӘиҜҜе·®пјҢ�пјҢпјҢпјҢ�пјҢиҖҢиҝҷдёӘиҜҜе·®е°ұжҳҜжҲ‘жүҖз•ҢиҜҙзҡ„вҖңеҫҒдҝЎиҜҜе·®вҖқпјҲCredit Scoring ErrorпјүпјҢ�пјҢпјҢпјҢ�пјҢеҚіпјҡCSE=|Z*-Z|�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ
жҲ‘们еҜ№еҫҒдҝЎиҜҜе·®зҡ„жңҹеҫ…жҳҜд»Җд№Ҳ�пјҹ�пјҹ�пјҹ�пјҹпјҹиҷҪ然жҳҜи¶Ҡе°Ҹи¶ҠеҘҪ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҖҺж ·жүҚеҚҺи®©CSEеҸҳе°Ҹе‘ў�пјҹ�пјҹ�пјҹ�пјҹпјҹж ·жң¬йҮҸдјҡжңүиө„еҠ©еҗ—�пјҹ�пјҹ�пјҹ�пјҹпјҹжңүпјҢ�пјҢпјҢпјҢ�пјҢеҸҜжҳҜиө„еҠ©дёҚеӨ§�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдҫӢеҰӮпјҡжҲ‘е‘ҠиҜүдҪ е…ЁеӨ©дёӢжҜҸдёҖдёӘдәәзҡ„жҖ§еҲ«пјҲжңЁжңүе…¶д»–дҝЎжҒҜпјүпјҢ�пјҢпјҢпјҢ�пјҢиҝҷдёӘж ·жң¬йҮҸеӨҹеӨ§дәҶжҠҠ�пјҹ�пјҹ�пјҹ�пјҹпјҹеҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢеҜ№еҫҒдҝЎиҖҢиЁҖпјҢ�пјҢпјҢпјҢ�пјҢиө„еҠ©жһҒе…¶жңүйҷҗ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮз”ұдәҺпјҢ�пјҢпјҢпјҢ�пјҢе…ідәҺеҫҒдҝЎиҖҢиЁҖпјҢ�пјҢпјҢпјҢ�пјҢжҖ§еҲ«дёҚжҳҜдёҖдёӘзү№ж®Ҡдё»иҰҒзҡ„жҢҮж ҮпјҢ�пјҢпјҢпјҢ�пјҢ并且иҝҷз…§ж—§е”ҜдёҖзҡ„жҢҮж Ү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮд»ҘжҳҜпјҢ�пјҢпјҢпјҢ�пјҢзңҹжӯЈзҡ„еҸҜд»Ҙй•Ңжұ°еҫҒдҝЎиҜҜе·®зҡ„иҰҒйўҶжҳҜпјҡеўһж·»XпјҢ�пјҢпјҢпјҢ�пјҢи®©Xзҡ„дҝЎжҒҜи¶ҠеҸ‘еҜҢеҺҡпјҢ�пјҢпјҢпјҢ�пјҢи®©Xзҡ„з»ҙеәҰеҸҳеҫ—жӣҙй«ҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдҫӢеҰӮпјҡд»ҘеүҚXеҶ…йҮҢеҸӘжңүж·ҳе®қзҡ„ж•°жҚ®пјҢ�пјҢпјҢпјҢ�пјҢзҺ°еңЁеҸҜд»ҘжҖқйҮҸеўһж·»дә¬дёңзҡ„пјӣпјӣ�пјӣ�пјӣ�пјӣд»ҘеүҚXеҶ…йҮҢеҸӘжңү收е…Ҙж°ҙе№іпјҢ�пјҢпјҢпјҢ�пјҢзҺ°еңЁеҸҜд»ҘжҖқйҮҸеўһж·»ж•ҷиӮІж°ҙе№іпјӣпјӣ�пјӣ�пјӣ�пјӣд»ҘеүҚXеҶ…йҮҢеҸӘжңүж¶ҲиҖ—ж•°жҚ®пјҢ�пјҢпјҢпјҢ�пјҢзҺ°еңЁеҸҜд»ҘжҖқйҮҸеўһж·»зӨҫдәӨдҝЎжҒҜ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸӘжңүеўһж·»й«ҳиҙЁйҮҸзҡ„XпјҢ�пјҢпјҢпјҢ�пјҢжүҚеҸҜд»ҘйҷҚдҪҺеҫҒдҝЎиҜҜе·®пјҢ�пјҢпјҢпјҢ�пјҢд»ҺиҖҢйҷҚдҪҺдҝЎиҙ·йЈҺйҷ©�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷе°ұйҡҫжҖӘпјҢ�пјҢпјҢпјҢ�пјҢйҷ©дәӣжүҖжңүеҫҒдҝЎдјҒдёҡзҡ„й«ҳз®ЎпјҢ�пјҢпјҢпјҢ�пјҢйғҪеҝҷдәҺжӢ“еұ•ж•°жҚ®жәҗпјҢ�пјҢпјҢпјҢ�пјҢеҜҢеҺҡиҮӘе·ұзҡ„X�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮе…ідәҺд»Җд№Ҳж ·зҡ„иЎҢдёҡгҖҒд»Җд№Ҳж ·зҡ„дјҒдёҡгҖҒйҖҡиҝҮд»Җд№Ҳж ·зҡ„ж–№ејҸпјҢ�пјҢпјҢпјҢ�пјҢжүҚеҸҜд»Ҙе‘Ҡз«Јж•°жҚ®еҲҶдә«зҡ„еҗҢзӣҹпјҢ�пјҢпјҢпјҢ�пјҢиҝҷжҳҜжҜҸдёҖдёӘеҫҒдҝЎдјҒдёҡйғҪиҰҒжҖқзҙўзҡ„й—®йўҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ

зҺ°еңЁжҲ‘们д»Ӣз»ҚдәҶеҫҒдҝЎиҜҜе·®иҝҷдёӘзңӢжі•�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҺҘдёӢжқҘзҡ„й—®йўҳжҳҜпјҡжҖҺж ·дёҲйҮҸCSE�пјҹ�пјҹ�пјҹ�пјҹпјҹжҲ‘们еҸҜд»ҘеҮҶзЎ®зҹҘйҒ“CSEжҳҜеҮ еӨҡеҗ—�пјҹ�пјҹ�пјҹ�пјҹпјҹиҷҪ然дёҚеҸҜиғҪ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮз”ұдәҺеңЁZ*е·ІзҹҘзҡ„жқЎд»¶дёӢпјҢ�пјҢпјҢпјҢ�пјҢиӢҘжҳҜиҝҳеҮҶзЎ®зҹҘйҒ“дәҶCSEпјҢ�пјҢпјҢпјҢ�пјҢйӮЈзӯүд»·дәҺеҮҶзЎ®зҹҘйҒ“дәҶZ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҖҢеҰӮеүҚжүҖиҝ°пјҢ�пјҢпјҢпјҢ�пјҢZжҳҜдёҚеҸҜиғҪеҮҶзЎ®зҹҘйҒ“зҡ„�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйӮЈд№ҲжҖҺж ·иҜ„д»·Z*зҡ„иҜҜе·®е‘ў�пјҹ�пјҹ�пјҹ�пјҹпјҹиҝҷжҳҜз»ҹи®ЎеӯҰеҸҰеӨ–дёҖдёӘдәҶдёҚиө·зҡ„еҲӣж„Ҹ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮе®ғиҜҙпјҡиӢҘжҳҜжҲ‘д»¬ж— жі•зҹҘйҒ“CSEзҡ„еҮҶзЎ®еҸ–еҖјпјҢ�пјҢпјҢпјҢ�пјҢйӮЈд№Ҳе°ұзӣҳз®—дёҖдёӢд»–зҡ„йў„жңҹпјҲExpectationпјүеҗ§�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮзқҖе®һз»ҶжғідёҖдёӢпјҢ�пјҢпјҢпјҢ�пјҢиҝҷдёҚжҳҜдёҖдёӘеҖјеҫ—зү№ж®ҠејҖеҝғзҡ„дәӢжғ…�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮз”ұдәҺпјҢ�пјҢпјҢпјҢ�пјҢдҪҶеҮЎжҲ‘们еҸҜд»ҘзҹҘйҒ“CSEзҡ„еҮҶзЎ®еҸ–еҖјпјҢ�пјҢпјҢпјҢ�пјҢе°ұжІЎжңүйЎ»иҰҒзӣҳз®—д»–зҡ„йў„жңҹдәҶ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮд№Ӣд»ҘжҳҜз”Ёйў„жңҹзҡ„CSEпјҲECSEпјҢ�пјҢпјҢпјҢ�пјҢExpected Credit Scoring ErrorпјүпјҢ�пјҢпјҢпјҢ�пјҢжҳҜз”ұдәҺжІЎжңүжӣҙеҘҪзҡ„жӯҘдјҗдәҶ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢдёҚз®ЎжҖҺж ·пјҢ�пјҢпјҢпјҢ�пјҢECSEеә”иҜҘжҳҜдёҖдёӘжңүз”Ёзҡ„е·Ҙе…·пјҢ�пјҢпјҢпјҢ�пјҢ并且жҳҜеҸҜд»ҘйҖҡиҝҮжЁЎеӯҗе’Ңзӣёе…ізҗҶи®әзӣҳз®—еҮәжқҘзҡ„�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮд»ҺзҗҶи®әдёҠи®ІпјҢ�пјҢпјҢпјҢ�пјҢ ECSEеҸҜд»Ҙжңүи®ёеӨҡз§Қе·®еҲ«зҡ„з•ҢиҜҙ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдҫӢеҰӮпјҡз»қеҜ№иҜҜе·®е’ҢеқҮж–№иҜҜе·®е°ұжҳҜдёӨдёӘеҸҜиғҪзҡ„е·®еҲ«йҖүжӢ©�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҜжҳҜпјҢ�пјҢпјҢпјҢ�пјҢж— и®әжҖҺж ·з•ҢиҜҙпјҢ�пјҢпјҢпјҢ�пјҢдёҖдёӘеҗҲзҗҶзҡ„ECSEеҝ…йңҖе…·еӨҮдёҖдәӣз®Җжңҙзҡ„зү№еҫҒ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдҫӢеҰӮпјҡиӢҘжҳҜECSE=0пјҢ�пјҢпјҢпјҢ�пјҢйӮЈд№Ҳе°ұдјҡжңүZ*=Z�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҲдҫӢеҰӮпјҢ�пјҢпјҢпјҢ�пјҢеҸӘиҰҒXзҡ„дҝЎжҒҜи¶ҠжқҘи¶ҠеӨҡпјҢ�пјҢпјҢпјҢ�пјҢECSEдјҡжһҜзҮҘдёӢйҷҚпјҢ�пјҢпјҢпјҢ�пјҢеҸҜжҳҜдёҚдјҡж— йҷҗйқ иҝ‘0�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ

зҹҘйҒ“ECSEеҸҲжҖҺж ·�пјҹ�пјҹ�пјҹ�пјҹпјҹдёәжӯӨпјҢ�пјҢпјҢпјҢ�пјҢжҲ‘们еҶҚзЈЁз»ғдёҖдёӢзҺӢе…Ҳз”ҹиҠқйә»дҝЎз”ЁеҲҶзҡ„й—®йўҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҮӯиҜҒзҺ°еңЁзҡ„иҝҷдёӘзҗҶи®әжЎҶжһ¶пјҢ�пјҢпјҢпјҢ�пјҢиҠқйә»ж”¶зҪ—дәҶдёҖдәӣе…ідәҺзҺӢе…Ҳз”ҹXзҡ„дҝЎжҒҜ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮз”ұдәҺзҺӢе…Ҳз”ҹеҫҲе°‘з”Ёж”Ҝд»ҳе®қпјҢ�пјҢпјҢпјҢ�пјҢд»ҘжҳҜXеҫҲжҳҜжңүйҷҗ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷдёӘзҡ„ж•ҲжһңжҳҜпјҢ�пјҢпјҢпјҢ�пјҢеҫҒдҝЎйў„и®ЎйҮҸZ*=630жҳҜдёҖдёӘеҫҲзҰҒз»қзЎ®зҡ„еҫ—еҲҶ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиӢҘжҳҜжҲ‘们еҸҜд»Ҙзӣҳз®—д»–зҡ„ECSEпјҢ�пјҢпјҢпјҢ�пјҢеҸҜиғҪжҳҜдёҖдёӘеҫҲеӨ§зҡ„ж•°еӯ—пјҲдҫӢеҰӮпјҡ50пјү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷиҜҙжҳҺпјҢ�пјҢпјҢпјҢ�пјҢзқҖе®һ630±2*50йғҪжҳҜзҺӢе…Ҳз”ҹзңҹе®һдҝЎз”Ёзҡ„еҗҲзҗҶеҸ–еҖји§„жЁЎ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжңҖе°ҸеҸҜд»ҘеҲ°530пјҲзіҹзі•йҖҸйЎ¶пјүпјҢ�пјҢпјҢпјҢ�пјҢжңҖеҘҪеҸҜд»ҘеҲ°730пјҲжһҒе…¶дјҳејӮпјү�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮзҺӢе…Ҳз”ҹпјҢ�пјҢпјҢпјҢ�пјҢд»Ҙе°Ҹдәәд№ӢеҝғпјҢ�пјҢпјҢпјҢ�пјҢеҒҡдёҖдёӘи…№й»‘зҡ„жҺЁж–ӯпјҡеҸҜиғҪпјҢ�пјҢпјҢпјҢ�пјҢдёәдәҶеўһж·»жӣҙеӨҡжӣҙеҜҢеҺҡзҡ„XпјҢ�пјҢпјҢпјҢ�пјҢиҠқйә»зҡ„дҝЎз”Ёеҫ—еҲҶйҮҢиҝҳдјҡеӨ„еҲҶеғҸзҺӢе…Ҳз”ҹиҝҷж ·дҝЎжҒҜдёҚе®Ңж•ҙзҡ„家дјҷпјҢ�пјҢпјҢпјҢ�пјҢиҖҢеӢүеҠұе®ҢжҲҗвҖңиҠқйә»дҪҝе‘ҪвҖқпјҢ�пјҢпјҢпјҢ�пјҢе…»жҲҗвҖңиҠқйә»д№ жғҜвҖқзҡ„з”ЁжҲ·�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ然иҖҢпјҢ�пјҢпјҢпјҢ�пјҢиҝҷдәӣйғҪжҳҜеңЁеўһж·»XпјҢ�пјҢпјҢпјҢ�пјҢйҷҚдҪҺECSEпјҢ�пјҢпјҢпјҢ�пјҢиҖҢж— е…ід№Һзңҹе®һзҡ„дҝЎз”Ё�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ
ECSEиҝҷж ·дёҖдёӘзҗҶи®әжЎҶжһ¶пјҢ�пјҢпјҢпјҢ�пјҢе…ідәҺжңӘжқҘзҡ„еҫҒдҝЎе®һи·өжңүд»Җд№Ҳе»әи®®�пјҹ�пјҹ�пјҹ�пјҹпјҹжҲ‘жғіиҮіе°‘жңүдёӨдёӘпјҡпјҲ1пјүе…ідәҺECSEеҫҲеӨ§зҡ„з”ЁжҲ·пјҢ�пјҢпјҢпјҢ�пјҢеә”иҜҘеӢҮж•ўең°иҜҙеҮәжқҘпјҢ�пјҢпјҢпјҢ�пјҢжҲ‘дёҚзӣёиҜҶдҪ пјҢ�пјҢпјҢпјҢ�пјҢеӣ жӯӨеҜ№дҪ зҡ„дҝЎз”Ёж— жі•иҜ„дј°�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷйҮҢзҡ„ж„ҸжҖқжҳҜпјҡжҲ‘дёҚзҹҘйҒ“дҪ жҳҜеҘҪдәәз…§ж—§еқҸдәәпјҢ�пјҢпјҢпјҢ�пјҢдёҚжү«йҷӨд»»дҪ•дёҖз§ҚеҸҜиғҪ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҷҪ然пјҢ�пјҢпјҢпјҢ�пјҢиӢҘжҳҜдҪ дёҖе®ҡзӣјж„ҝжҲ‘дёәдҪ жҸҗдҫӣдёҖдёӘиҜ„дј°пјҢ�пјҢпјҢпјҢ�пјҢйӮЈд№ҲиҜ·жҸҗдҫӣеҜҢи¶ізҡ„XдҝЎжҒҜпјҢ�пјҢпјҢпјҢ�пјҢзӣҙеҲ°ECSEйҷҚеҲ°зҗҶжғізҡ„ж°ҙе№і�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷдёӘиҰҒйўҶзҡ„еҲ©зӣҠжҳҜе®№жҳ“ж“ҚдҪңпјҢ�пјҢпјҢпјҢ�пјҢеҸҜжҳҜејұзӮ№жҳҜиҰҒжұӮеӨӘй«ҳ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҮӯиҜҒиҝҷдёӘиҰҒжұӮпјҢ�пјҢпјҢпјҢ�пјҢжҲ‘зӣёдҝЎз»қеӨ§еӨ§йғҪдә’иҒ”зҪ‘з”ЁжҲ·иғҪеӨҹжҸҗдҫӣеә”еҫҒдҝЎжңәжһ„зҡ„дҝЎжҒҜжҳҜдёҚе……еҲҶзҡ„пјҢ�пјҢпјҢпјҢ�пјҢжҳҜиҫҫдёҚеҲ°иҝҷдёӘж ҮеҮҶзҡ„�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮпјҲ2пјүеҸҰеӨ–дёҖдёӘи§ЈеҶіж–№жЎҲе°ұжҳҜпјҡжҲ‘иҜ„дј°дәҶпјҢ�пјҢпјҢпјҢ�пјҢеҸҜжҳҜжұҮжҠҘдёҖдёӢECSEпјҢ�пјҢпјҢпјҢ�пјҢжҸҗйҶ’дёҖдёӢз”ЁжҲ·пјҢ�пјҢпјҢпјҢ�пјҢе®үеҚҡз”өз«һиҜ„дј°иҜҜе·®йў„и®ЎдјҡжңүеӨҡеӨ§�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷж ·еҒҡзҡ„дјҳзӮ№жҳҜпјҡи¶ҠеҸ‘科еӯҰеҮҶзЎ®пјҢ�пјҢпјҢпјҢ�пјҢ并且еҸҜд»Ҙз¬јзҪ©жӣҙеӨҡзҡ„з”ЁжҲ·�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮеҸҜжҳҜејұзӮ№жҳҜеӨӘдё“дёҡпјҢ�пјҢпјҢпјҢ�пјҢе…ідәҺйҖҡдҝ—з”ЁжҲ·ж¬ еҘҪжҮӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдёҖдёӘжӣҙеҘҪзҡ„еҒҡжі•пјҢ�пјҢпјҢпјҢ�пјҢд№ҹи®ёжҳҜжҸҗдҫӣдёҖдёӘе…ідәҺZзҡ„еҢәй—ҙйў„и®Ў�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдёәжӯӨпјҢ�пјҢпјҢпјҢ�пјҢз»ҹи®ЎеӯҰдёӯзҡ„зҪ®дҝЎеҢәй—ҙпјҲжҲ–иҖ…йў„жөӢеҢәй—ҙпјүе°ҶеӨ§жңүз”ЁжӯҰд№Ӣең°�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮдёҚз®ЎжҳҜе“ӘдёҖз§ҚйҖүжӢ©пјҢ�пјҢпјҢпјҢ�пјҢпјҲ1пјүжҲ–иҖ…пјҲ2пјүпјҢ�пјҢпјҢпјҢ�пјҢиӢҘжҳҜжІЎжңүеҜ№еҫҒдҝЎиҜҜе·®зҡ„еҗҲзҗҶз®ЎжҺ§пјҢ�пјҢпјҢпјҢ�пјҢжҲ‘们е°ҶзңӢеҲ°зҡ„жҳҜеҫҒдҝЎжіӣж»Ҙ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮжҲ‘们е°ҶзңӢеҲ°и¶ҠжқҘи¶ҠеӨҡзҡ„дјҒдёҡжңәжһ„еҜ№дёӘдәәдҝЎз”ЁжҢҮжүӢз”»и„ҡпјҢ�пјҢпјҢпјҢ�пјҢиҖҢйҖҡдҝ—з”ЁжҲ·дёҖи„ёиҢ«з„¶пјҢ�пјҢпјҢпјҢ�пјҢеҫҲжҳҜиў«еҠЁпјҢ�пјҢпјҢпјҢ�пјҢиҝӣиҖҢеј•иө·жҒјжҖ’�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮиҝҷеҜ№ж•ҙдёӘеҫҒдҝЎиЎҢдёҡдёҚжҳҜеҘҪж–°й—»�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ
еӣ жӯӨжҖ»з»“дёҖдёӢпјҡиҰҒйҳ»жӯўеҫҒдҝЎжіӣж»ҘпјҢ�пјҢпјҢпјҢ�пјҢе°ұиҰҒеҮҶзЎ®иҜ„дј°еҫҒдҝЎиҜҜе·®�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮе’ӢиҜ„д»·�пјҹ�пјҹ�пјҹ�пјҹпјҹи®ӨзңҹеӯҰд№ з»ҹи®ЎеӯҰзҗҶи®әе‘—�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮйўқпјҢ�пјҢпјҢпјҢ�пјҢеҜ№дёҚиө·еҲ—дҪҚпјҢ�пјҢпјҢпјҢ�пјҢе…ңдәҶдёҖдёӘеҫҲеӨ§зҡ„еңҲеӯҗпјҢ�пјҢпјҢпјҢ�пјҢжңҖеҗҺзҡ„з»“и®әжҳҜпјҡз»ҹи®ЎеӯҰеҘҪпјҢ�пјҢпјҢпјҢ�пјҢз»ҹи®ЎеӯҰеҫҲдё»иҰҒпјҢ�пјҢпјҢпјҢ�пјҢз»ҹи®ЎеӯҰйғҪжІЎеӯҰеҘҪпјҢ�пјҢпјҢпјҢ�пјҢе№Іе•Ҙе•ҘдёҚеҸҜпјҢ�пјҢпјҢпјҢ�пјҢеҗғеҳӣеҳӣдёҚйҰҷпјҢ�пјҢпјҢпјҢ�пјҢж•ҲжһңеҫҲдёҘйҮҚ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ�гҖӮ










